
Bonjour à tous,
En arrivant un peu après la bataille, j’avais un vieux Zbook (i7-1165G7, 32gb de ram, Nvidia T500 4go) qui trainait et je me suis demandé ce que je pouvais en faire.
Il se trouve qu’avec les modèles d’IA qui s’améliorent en permanence et demandent de moins en moins de ressources, on peut faire tourner des trucs sympas sur une configuration modeste.
Voici donc un article qui explique comment installer Ollama (un outil de gestion et de lancement des modèles d’IA) et Open WebUI (une interface web pour le premier outil).
Ces outils sont disponibles sur Windows comme sur Linux (et Mac), mais j’avais déjà un Windows 11 qui tournait sur cette machine et je n’avais pas envie de me battre avec les habituelles emmerdes au niveau de cuda et des drivers Nvidia sous Linux, donc tout sera fait sous Windows.
Dernière précision, on vise une installation headless qui tourne via des services Windows.
Installation des prérequis
Avant tout, créez vous un compte dédié avec des droits d’administrateur local, “IA” dans mon cas.
On va ensuite installer 3 outils différents :
- VCRedist AIO pour télécharger tous les redistribuables visuals C++ (différentes versions pour certains modèles ou OpenWeb UI et Ollama)
- Python 3.11
- NSSM pour créer les services qui feront tourner les deux logiciels
Lancez un powershell en administrateur et téléchargez et installez tous les redistribuables VC++ :
$url = 'https://github.com/abbodi1406/vcredist/releases/latest/download/VisualCppRedist_AIO_x86_x64.exe' $downloadPath = Join-Path -Path $env:TEMP -ChildPath "VisualCppRedist_AIO_x86_x64_latest.exe" Invoke-WebRequest -Uri $url -OutFile $downloadPath Start-Process -FilePath $downloadPath -ArgumentList '/quiet', '/norestart' -Wait
Installez ensuite Python 3.11 et NSSM :
winget install Python.Python.3.11 winget install NSSM.NSSM
Mettez enfin à jour PIP :
python.exe -m pip install --upgrade pip
Installation de Ollama
L’installateur de Ollama se met par défaut dans l’appdata de l’utilisateur, ce qui ne va pas pour faire un service, on va donc le télécharger manuellement :
mkdir C:\_IA\ollama-windows-amd64 cd C:\_IA\ollama-windows-amd64 Invoke-WebRequest -Uri "https://github.com/ollama/ollama/releases/latest/download/ollama-windows-amd64.zip" -OutFile "ollama-windows-amd64.zip" Expand-Archive -Path "ollama-windows-amd64.zip" -DestinationPath "." -Force
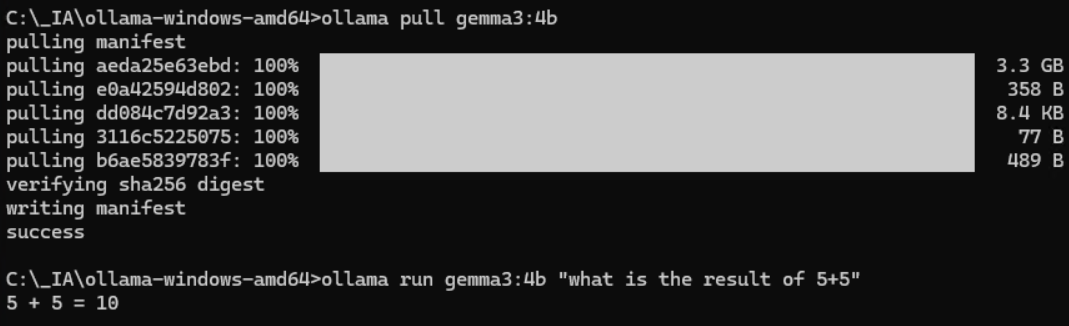
Testez le fonctionnement d’Ollama avec les commandes suivantes et un modèle de test léger :
ollama pull gemma3:4b ollama run gemma3:4b "what is the result of 5+5"
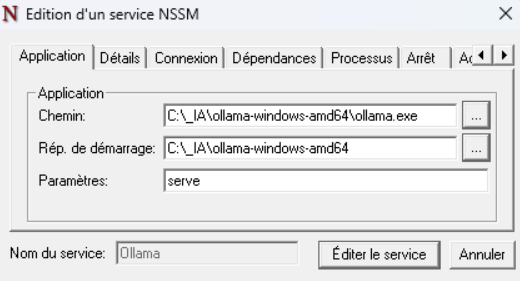
Installez maintenant un service pour Ollama via la commande suivante :
nssm install Ollama
Les informations de service sont les suivantes :
- Path: C:\_IA\ollama-windows-amd64\ollama.exe
- Startup directory: C:\_IA\ollama-windows-amd64
- Arguments: serve
- Details → Display name: Ollama
- Log on → Account: Local System
Enregistrez et lancez le service.
Installation de Open WebUI
Installez la dernière version de Open WebUI via PIP :
pip install open-webui
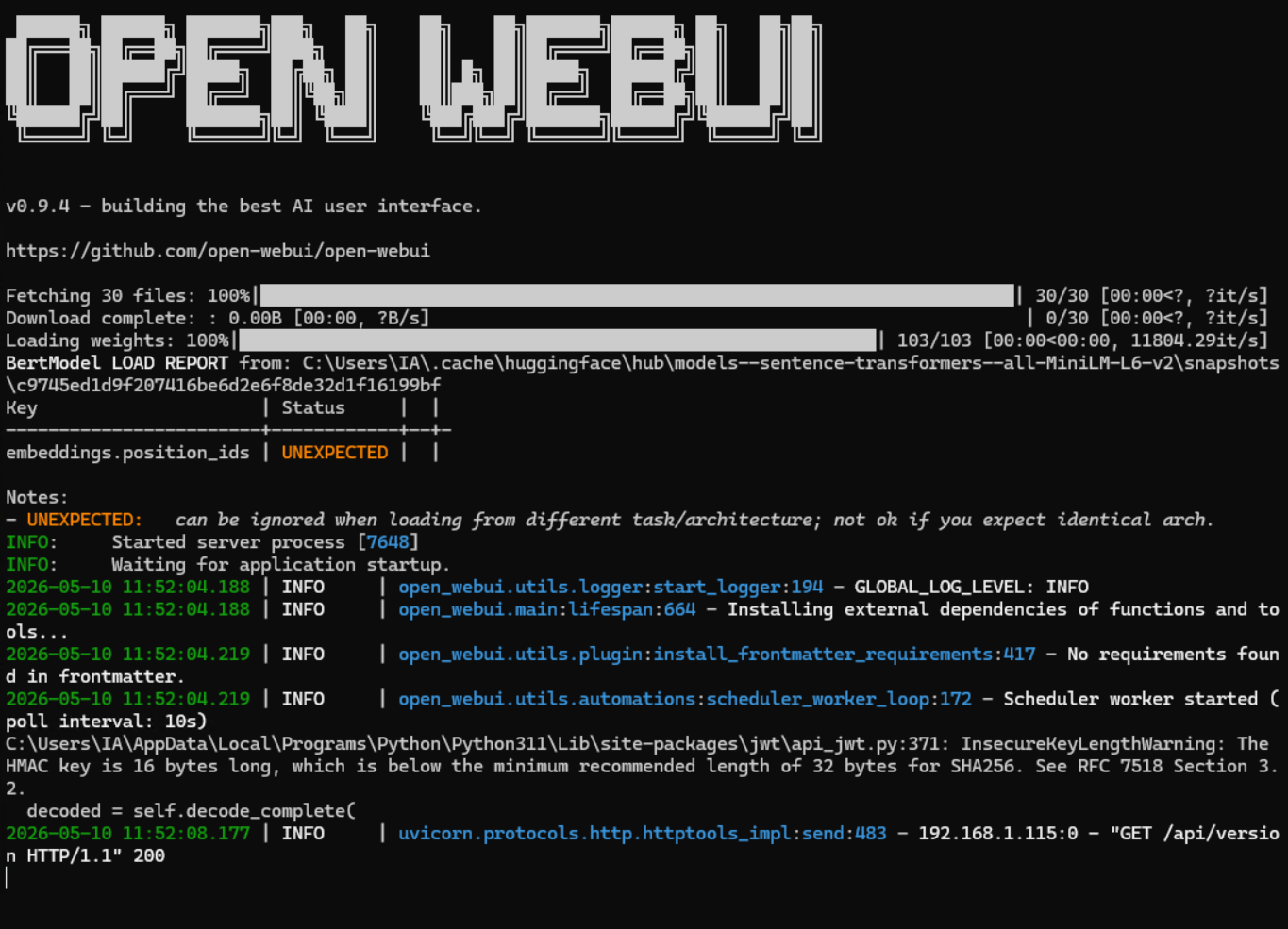
Lancez maintenant open-webui et tentez de vous connecter sur l’url suivante lorsqu’il aura démarré : http://localhost:8080
open-webui serve
Si le test est OK, créez un fichier bat à cet emplacement :
- C:\_Scripts\open-webui.bat
Remplissez-le avec ce qui suit :
@echo off cd /d C:\Users\IA\AppData\Local\Programs\Python\Python311\Scripts\ open-webui.exe serve
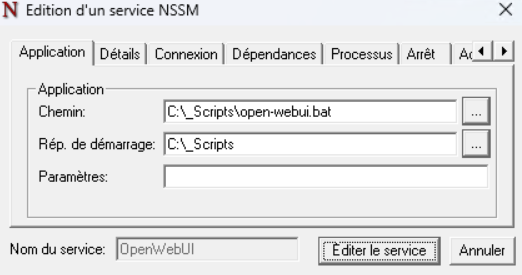
Ensuite, installez le service avec la commande suivante :
nssm install OpenWebUI
- Path: C:\_Scripts\open-webui.bat
- Startup directory: C:\_Scripts
- Startup: Automatic
Démarrez ensuite le service.
Utilisation de Open WebUI
Une fois sur l’interface (http://localhost:8080), créez votre compte.
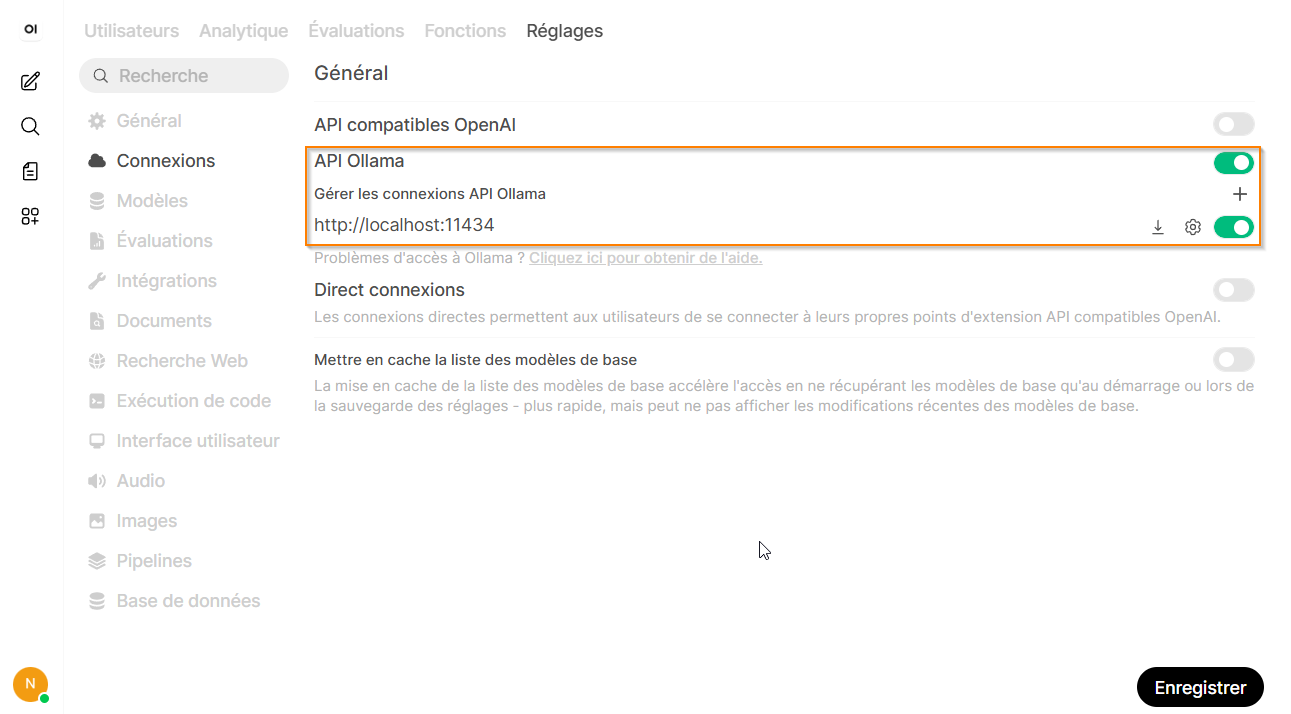
Allez ensuite dans l’administration pour renseigner l’API de Ollama dans Réglages -> Connexions :
Vous pourrez ensuite discuter avec votre modèle directement :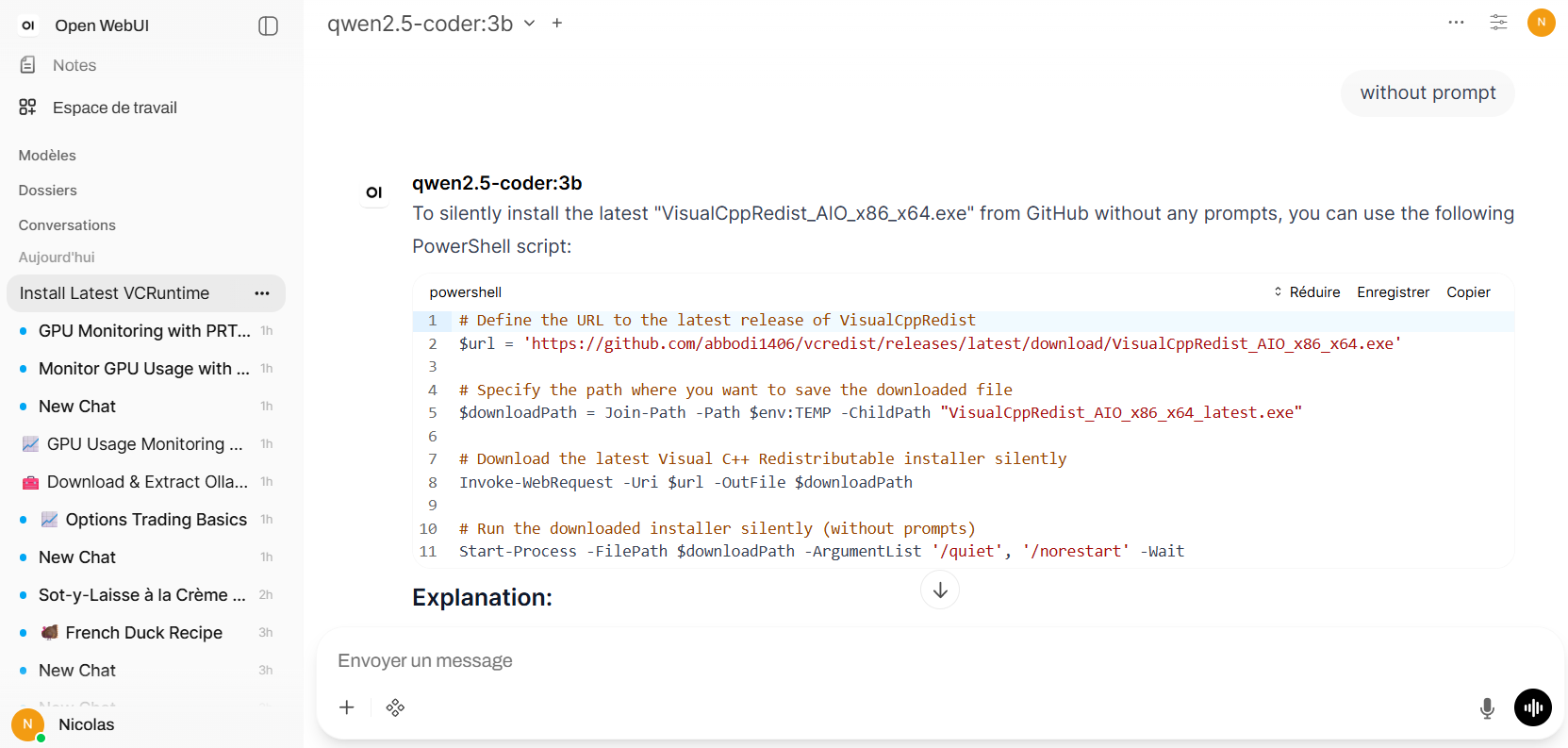
Si vous en avez plusieurs, la sélection du modèle se fait en haut :
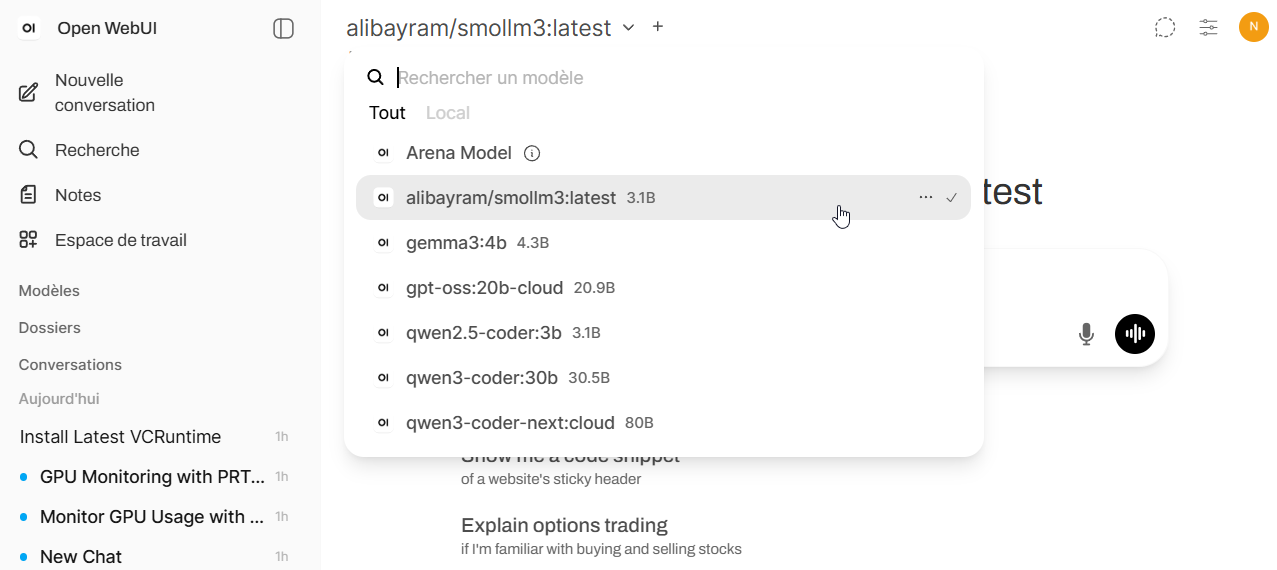
Pour ma part, je suis parti sur les modèles suivants :
- alibayram/smollm3:latest : Modèle générique, un des plus rapides et précis dans sa catégorie
- gemma3:4b : Pareil qu’au dessus mais un poil plus évolué
- qwen2.5-coder:3b : Modèle dédié au code et aux raisonnements technique, version allégée
- qwen3-coder:30b : Le même, mais en beaucoup plus puissant
- gpt-oss:20b-cloud : Un des derniers modèles générique d’OpenAi qui tourne dans le cloud Ollama
- qwen3-coder-next:cloud : Modèle dédié au code plus évolué qui tourne dans le cloud Ollama
Intégration de modèles cloud
Comme vous l’avez vu avant, j’ai deux modèles qui sont marqués “cloud“.
Via un compte Ollama et la commande suivante, vous pouvez déporter vos demandes sur des modèles qui tourneront dans le cloud depuis votre interface (pour certaines demandes complexes par exemple).
ollama signin
Attention : Ces modèles tournent sur un cloud public, sur des serveurs US.
Une liste des modèles est disponible ici : https://ollama.com/search
Open WebUI derrière un reverse proxy NGINX
Vous pouvez ouvrir votre Open WebUI sur le monde via un reverse proxy NGINX (et y ajouter du SSL par la même occasion).
Voici le vhost que j’utilise pour se faire :
upstream openwebui {
server 192.168.1.4:8080;
keepalive 128;
keepalive_timeout 1800s;
keepalive_requests 10000;
}
server {
listen 443 ssl http2;
server_name ia.nicolas-simond.ch;
# SSL configuration...
ssl_certificate /etc/letsencrypt/live/nicolas-simond.ch/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/nicolas-simond.ch/privkey.pem;
# Compression - EXCLUDE streaming content types
gzip on;
gzip_types text/plain text/css application/javascript image/svg+xml;
# DO NOT include: application/json, text/event-stream
# API endpoints - streaming optimized
location /api/ {
proxy_pass http://openwebui;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# CRITICAL: Disable all buffering for streaming
gzip off;
proxy_buffering off;
proxy_request_buffering off;
proxy_cache off;
tcp_nodelay on;
add_header X-Accel-Buffering "no" always;
add_header Cache-Control "no-store" always;
# Extended timeouts for LLM completions
proxy_connect_timeout 1800;
proxy_send_timeout 1800;
proxy_read_timeout 1800;
}
# WebSocket endpoints
location ~ ^/(ws/|socket\.io/) {
proxy_pass http://openwebui;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
gzip off;
proxy_buffering off;
proxy_cache off;
# 24-hour timeout for persistent connections
proxy_connect_timeout 86400;
proxy_send_timeout 86400;
proxy_read_timeout 86400;
}
# Static assets - CAN buffer and cache
location /static/ {
proxy_pass http://openwebui;
proxy_buffering on;
proxy_cache_valid 200 7d;
add_header Cache-Control "public, max-age=604800, immutable";
}
# Default location
location / {
proxy_pass http://openwebui;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Mise à jour des applications et des modèles
Vous pourrez mettre à jour les deux applications et les modèles via le script suivant (selon la taille de vos modèles, lancez-le une fois par semaine) :
#Stop Services
Stop-Service -Name (@('ollama', 'openwebui')) -Force
#Upgrade Open-WebUI
pip install open-webui --upgrade
#Upgrade Ollama
cd C:\_IA\ollama-windows-amd64
Invoke-WebRequest -Uri "https://github.com/ollama/ollama/releases/latest/download/ollama-windows-amd64.zip" -OutFile "ollama-windows-amd64.zip"
Expand-Archive -Path "ollama-windows-amd64.zip" -DestinationPath "." -Force
#Wait for operation to finish
Start-Sleep -Seconds 5
#Start Services
Start-Service -Name (@('ollama', 'openwebui')) -Verbose
#Update models
ollama list |
Select-Object -Skip 1 |
ForEach-Object {
$null -match '^\s*(\S+)' # reset $Matches
if ($_ -match '^\s*(\S+)') {
$model = $Matches[1]
Write-Host "updating $model model"
ollama pull $model > $null
}
}
Et voilà, c’est tout pour le moment.
On verra par la suite comment connecter les modèles locaux à Internet et peut-être même la génération d’images 🙂